
Introduction
While it is generally believed that reliability prediction methods should beused to aid product design and product development, the integrity andauditability of the traditional prediction methods have been found to bequestionable, in that the models do not predict field failures, cannot be usedfor comparative purposes, and present misleading trends and relations. Thispaper presents a historical overview of reliability predictions for electronics,discusses the traditional reliability prediction approaches, and then presentsan effective alternative which is becoming widely accepted.
Historical Perspective to the Traditional Reliability Prediction Models
Stemming from a perceived need to place a figure of merit on a system’sreliability during World War II, the U.S. government procurement agencies soughtstandardization of requirement specifications and a prediction process. The viewwas that without standardization, each supplier could develop their ownpredictions based on their own data, and it would be difficult to evaluatesystem predictions against requirements based on components from differentsuppliers, or to compare competitive designs for the same component or system.
Reliability prediction and assessment SPECs can be traced to November 1956,with the publication of the RCA release TR-1100, “Reliability StressAnalysis for Electronic Equipment”, which presented models for computingrates of component failures. This publication was followed by the “RADCReliability Notebook” in October 1959, and the publication of a militaryreliability prediction handbook format known as MIL-HDBK-217.
In MIL-HDBK-217A, a single-point failure rate of 0.4 failures per millionhours was listed for all monolithic integrated circuits, regardless of theenvironment, the application, the materials, the architecture, the device power,the manufacturing processes or the manufacturer. This single-valued failure ratewas indicative of the fact that accuracy and science were of less concern thanstandardization.
The advent of more complex microelectronic devices continuously pushed theMIL-HDBK-217 beyond reasonable limits, as was seen for example in the inabilityof MIL-HDBK-217B models to address 64K or 256K RAM. In fact, when the RAM modewas used for the 64K capability common at that time, the resulting computed meantime between failures was 13 seconds, many orders of magnitude from the MTBFexperienced in real life. As a result of such incidents, new versions ofMIL-HDBK-217 appeared about every seven years to “band-aid” theproblems.
Today, the U.S. government and the military, as well as various U.S. andEuropean manufacturers of electronic components, printed wiring and circuitboards and electronic equipment and systems, still subscribe to the traditionalreliability prediction techniques (e.g. MIL-HDBK-217 and progeny)1in some manner, although sometimes unknowingly.
But with studies conducted by the National Institute of Standards andTechnology (NIST), Bell Northern Research, the U.S. Army, Boeing, Honeywell,Delco and Ford Motor Co., it is now clear that the approach has been damaging tothe industry and a change is needed.
Problems with the Traditional Approach to Reliability Prediction
Problems that arise with the traditional reliability prediction methods andsome of the reasons these problems exist are described below.
(1) Up-to-date collection of the pertinent reliability data needed for thetraditional reliability prediction approaches is a major undertaking, especiallywhen manufacturers make yearly improvements. Most of the data used by thetraditional models is out-of-date. For example, the connector models inMIL-HDBK-217 have not been updated for at least 10 years, and were formulatedbased on data 20 years old.
Nevertheless, reliance on even a single outdated or poorly conceivedreliability prediction approach can prove costly for systems design anddevelopment. For example, the use of military allocation documents (JIAWG),which utilizes the MIL-HDBK-217 approach upfront in the design process,initially led to design decisions maximizing the junction temperature in theF-22 advanced tactical fighter electronics to 60°C and in the Comanchelight helicopter to 65°C. Boeing noted that, “The System SegmentSpecification normal cooling requirements were in place due to militaryelectronic packaging reliability allocations and the backup temperature limitsto provide stable electronic component performance. The validity of thejunction temperature relationship to reliability is constantly in question andunder attack as it lacks solid foundational data.”
For the Comanche, cooling temperatures as low as -40°C at theelectronic’s rails were at one time required to obtain the specified junctiontemperatures; even though the resulting temperature cycles were known toprecipitate standing water as well as many unique failure mechanisms. Slightchanges have been made in these programs when these problems surfaced, butscheduling costs cannot be recovered.
(2) In general, equipment removals and part failures are not equal. Oftenfield removed parts are re-tested as operational (called re-test OK, orfault-not-found, or could-not duplicate) and the true cause of “failure”is never determined. As the focus of reliability engineering has been onprobabilistic assessment of field data, rather than on failure analysis, it hasgenerally been perceived to be cheaper for a supplier to replace a failedsubsystem (such as a circuit card) and ignore how the card failed.
(3) Many assembly failures are not component-related but due to an error insocketing, calibration or instrument reading or due to the improperinterconnection of components during a higher level assembly process. Today,reliability limiting items are much more likely to be in the system design (suchas misapplication of a component, inadequate timing analysis, lack of transientcontrol, stress-margins oversights), than in a manufacturing or design defect inthe device.
(4) Failure of the component is not always due to a component-intrinsicmechanism but can be caused by: (i) an inadvertent over-stress event afterinstallation; (ii) latent damage during storage, handling or installation aftershipment; (iii) improper assembly into a system; or (iv) choice of the wrongcomponent for use in the system by either the installer or designer. Variablestress environments can also make a model inadequate in predicting fieldfailures. For example, one Westinghouse fire control radar has been used in afighter aircraft, a bomber, and on the top mast of a ship, each with its uniqueconfiguration, packaging, reliability and maintenance requirements.
(5) Electronics do not fail at a constant rate, as predicted by the models. The models were originally used to characterize device reliability becauseearlier data was tainted by equipment accidents, repair blunders, inadequatefailure reporting, reporting of mixed age equipment, defective records ofequipment operating times, mixed operational environmental conditions. Thetotality of these effects conspired to produce what appeared to be anapproximately constant hazard rate. Further, earlier devices had severalintrinsic failure mechanisms which manifested themselves as severalsubpopulations of infant mortality and wear-out failures resulting in a constantfailure rate. The above assumptions of constant failure rate do not hold truefor present day devices.
(6) The reliability prediction models are based upon industry-average valuesof failure rates, which are neither vendor- nor device-specific. For example,failures may come from defects caused by uncontrolled fabrication methods, someof which were unknown and some of which were simply too expensive to control(i.e. the manufacturer took a yield loss, rather than putting more money tocontrol fabrication). In such cases, the failure was not representative of thefield failures upon which the reliability prediction was based.
(7) The reliability prediction was based upon an inappropriate statisticalmodel. For example, a failure in a lot of radio-frequency amplifiers wasdetected at Westinghouse in which the insulation of a wire was rubbed offagainst the package during thermal cycling. This resulted in an amplifier short.X-ray inspection of the amplifier during failure analysis confirmed thisproblem. The fact that a pattern failure (as opposed to a random failure)existed under the given conditions, proved that the original MIL-HDBK-217modeling assumptions were in error, and that either an improvement in design,improved quality, or inspection was required.
(8) The traditional reliability prediction approaches can produce what arelikely to be highly variable assessments. As one example, the predictedreliability, using different prediction handbooks, for a memory board with 7064k DRAMS in a “ground benign” environment at 40°C, varied from700 FITS to 4,240,460 FITS. Overly optimistic predictions may prove fatal.Overly pessimistic predictions can increase the cost of a system (e.g., throughexcessive testing, or a redundancy requirement), or delay or even terminatedeployment. Thus, these methods should not be used for preliminary assessments,baselining or initial design trade-offs.
An Alternative Approach: Physics-of-Failure
In Japan, Taiwan, Singapore, Malaysia, the U.K. Ministry of Defense and manyof the leading U.S. commercial electronics companies, the traditional methods ofreliability prediction have been abandoned. Instead, they use reliabilityassessment techniques, that are based on the root-cause analysis of failuremechanism, failure modes and failures causing stresses. This approach, calledphysics-of-failure, has proven to be effective in the prevention, detection, andcorrection, of failures associated with design, manufacture and operation of aproduct.
The physics-of-failure (PoF) approach to electronics products, is founded onthe fact that failure mechanisms are governed by fundamental mechanical,electrical, thermal, and chemical processes. By understanding the possiblefailure mechanisms, potential problems in new and existing technologies can beidentified and solved before they occur.
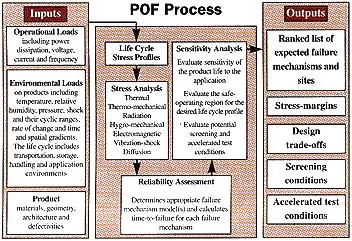
The PoF approach begins within the first stages of design (see Figure 1). ADesigner defines the product requirements, based on the customer’s needs and thesupplier’s capabilities. These requirements can include the product’sfunctional, physical, testability, maintainability, safety, and serviceabilitycharacteristics. At the same time, the service environment is identified, firstbroadly as aerospace, automotive, business office, storage, or the like, andthen more specifically as a series of defined temperature, humidity, vibration,shock, or other conditions. The conditions are either measured, or specified bythe customer. From this information, the designer, usually with the aid of acomputer, can model the thermal, mechanical, electrical, and electrochemicalstresses acting on the product.
Next, stress analysis is combined with knowledge about the stress responseof the chosen materials and structures to identify where failure might occur(failure sites), what form it might take (failure modes), and how it might takeplace (failure mechanisms). Failure is generally caused by one of the fourfollowing types of stresses: mechanical, electrical, thermal, or chemical, andit generally results either from the application of a single overstress, or bythe accumulation of damage over time from lower level stresses. Once thepotential failure mechanisms have been identified, the specific failuremechanism model is employed. The reliability assessment consists of calculatingthe time to failure for each potential failure mechanism, and then, using theprinciple that a chain is only as strong as its weakest link, choosing thedominant failure sites and mechanisms as those resulting in the least time tofailure. The information from this assessment can be used to determine whether aproduct will survive for its intended application life, or it can be used toredesign a product for increased robustness against the dominant failuremechanisms. The physics-of-failure approach is also used to qualify design andmanufacturing processes to ensure that the nominal design and manufacturingspecifications meet or exceed reliability targets.
Computer software has been developed by organizations such as Phillips andthe CALCE EPRC at the University of Maryland, to conduct a physics-of-failureanalysis at the component level. Numerous organizations have PoF software whichis used at the circuit card level. These software tools make design,qualification planing and reliability assessment, manageable and timely.
Summary Comments
The physics-of-failure approach has been used quite successfully for decadesin the design of mechanical, civil and aerospace structures. This approach isalmost mandatory for buildings and bridges, because the sample size is usuallyone, affording little opportunity for testing the completed product, or forreliability growth. Instead, the product must work properly the first time,even though it often relies on unique materials and architectures placed inunique environments.
Today, the PoF approach is being demanded by (1) suppliers to measure howwell they are doing and to determine what kind of reliability assurances theycan give to a customer and (2) by customers to determine that the suppliers knowwhat they are doing and that they are likely to deliver what is desired. Inaddition, PoF is used by both groups to assess and minimize risks. Thisknowledge is essential, because the supplier of a product which fails in thefield loses the customer’s confidence and often his repeat business, while thecustomer who buys a faulty product endangers his business and possibly thesafety of his customers.
In terms of the U.S. military, the U.S. Army has discovered that theproblems with the traditional reliability prediction techniques are enormous andhave canceled the use of MIL-HDBK-217 in Army specifications. Instead they havedeveloped Military Acquisition Handbook-179A which recommends best commercialpractices, including physics-of-failure.
Reference
The traditional approach to predicting reliability iscommon to various international handbooks.
[MIL-HDBK-217 1991;TR-TSY-000332 1988; HRDS 1995; CNET 1983; SN 29500 1986]; all derived from somepredecessor of MIL-HDBK-217.


