
Uncertainty analysis is the process of estimating the uncertainty in a result calculated from measurements with known uncertainties. Uncertainty analysis uses the equations by which the result was calculated to estimate the effects of measurement uncertainties on the value of the result.
Uncertainty analysis is used in the planning stages of an experiment to judge the suitability of the instrumentation; during the data-taking phase to judge whether the scatter on repeated trials is “normal” or means that something has changed; and in reporting the results, to describe the range believed to contain the true value.
The mathematics of uncertainty analysis is based on the statistical treatment of error but using uncertainty analysis does not require knowledge of statistics. The possible errors in each measurement are assumed “normally distributed”; the error in each measurement is assumed independent of the error in any other measurement, and the error in every measurement is described at the same confidence level. The procedures described herein are for “Single-Sample” uncertainty analysis: uncertainty estimates are calculated for each data set, individually. When many data sets are averaged before the result is calculated, different equations are used.
The Mathematical Background
The standard form for expressing a measurement is:
![]() (1)This is interpreted as follows: The odds are 20/1 that the true value of x is within +/-
(1)This is interpreted as follows: The odds are 20/1 that the true value of x is within +/- ![]() x of the recorded value. Assuming the true value is fixed by the process, and therefore remains constant, Eq. 1 means that if a large number measurements (each with a different measurement error) were made at the same test condition, using a wide variety of instruments (each with a different calibration error), the results would most likely center around the recorded value and have a “normal” distribution with a standard deviation of
x of the recorded value. Assuming the true value is fixed by the process, and therefore remains constant, Eq. 1 means that if a large number measurements (each with a different measurement error) were made at the same test condition, using a wide variety of instruments (each with a different calibration error), the results would most likely center around the recorded value and have a “normal” distribution with a standard deviation of ![]() x/2.When the result is a function of only one variable, the uncertainty in the result is:
x/2.When the result is a function of only one variable, the uncertainty in the result is:
![]() (2)The numerical approximation to the uncertainty in R is found by calculating the value of R twice: once with x augmented by
(2)The numerical approximation to the uncertainty in R is found by calculating the value of R twice: once with x augmented by ![]() x and once with the value of x at its recorded value, and subtracting the values.When more than one measurement is used in calculating the result, R, the uncertainty in R can be estimated in two ways: “worst case combination” and “constant odds”.
x and once with the value of x at its recorded value, and subtracting the values.When more than one measurement is used in calculating the result, R, the uncertainty in R can be estimated in two ways: “worst case combination” and “constant odds”.
The “worst case combination” is highly unlikely (400/1 against, tbr two variables each at 20/1 ), What is generally wanted is the uncertainty in the result, at the same odds used in estimating the measurement errors: the “constant odds” combination. This can be achieved by:
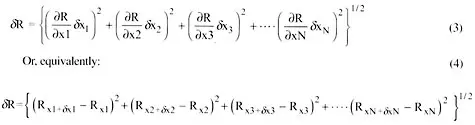 In executing Eq. 4, each term is calculated with only one variable augmented by its uncertainty interval, all others being at their recorded values. Eq. 3 is the classical analytical form for uncertainty analysis. It requires a separate set of equations for calculating the uncertainty. As an experiment evolves with experience, it is hard to ensure that the uncertainty equation set is kept current. When Eq. 4 is used, the uncertainty analysis is always current. Furthermore, the uncertainty is always calculated for every data set. On-line uncertainty analysis keeps the uncertainty in the results constantly visible, making it less likely that highly uncertain results will escape unnoticed.
In executing Eq. 4, each term is calculated with only one variable augmented by its uncertainty interval, all others being at their recorded values. Eq. 3 is the classical analytical form for uncertainty analysis. It requires a separate set of equations for calculating the uncertainty. As an experiment evolves with experience, it is hard to ensure that the uncertainty equation set is kept current. When Eq. 4 is used, the uncertainty analysis is always current. Furthermore, the uncertainty is always calculated for every data set. On-line uncertainty analysis keeps the uncertainty in the results constantly visible, making it less likely that highly uncertain results will escape unnoticed.
Table 1
Calculating the uncertainty in h by sequentially perturbing the inputs to a spreadsheet
Sequentially Perturbed Data
| Input | Est. Unc. | Data | In each col., the title variable has been increased by its uncertainty | ||||||||
| Variables | W | A | To | Tcool | Tboard | Twall | Stef-Boltz | Emmis | K | ||
| W | 0.5 | 4.000 | 4.500 | 4.000 | 4.000 | 4.000 | 4.000 | 4.000 | 4.000 | 4.000 | 4.000 |
| (indicated) watts | |||||||||||
| A,m2 | 2.50E-06 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| To, C | 1 | 80.000 | 80.000 | 80.000 | 81.000 | 80.000 | 80.000 | 80.000 | 80.000 | 80.000 | 80.000 |
| Tcool, C | 2 | 40.000 | 40.000 | 40.000 | 40.000 | 42.000 | 40.000 | 40.000 | 40.000 | 40.000 | 40.000 |
| Tboard, C | 2 | 55.000 | 55.000 | 55.000 | 55.000 | 55.000 | 57.000 | 55.000 | 55.000 | 55.000 | 55.000 |
| Twall, C | 2 | 55,000 | 55.000 | 55.000 | 55.000 | 55.000 | 55.000 | 57.000 | 55.000 | 55.000 | 55.000 |
| Stef/Bolt z | 0 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Emissivit y | 0.1 | 0.800 | 0.800 | 0.800 | 0.800 | 0.800 | 0.800 | 0.800 | 0.800 | 0.900 | 0.800 |
| Sh Fact, K | 0.01 | 0.060 | 0.060 | 0.060 | 0.060 | 0.060 | 0.060 | 0.060 | 0.060 | 0.060 | 0.070 |
| Q-Cond | 1.500 | 1.500 | 1.500 | 1.560 | 1.500 | 1.380 | 1.500 | 1.500 | 1.500 | 1.750 | |
| Q-Rad | 0.287 | 0.287 | 0.287 | 0.300 | 0.287 | 0.287 | 0.266 | 0.287 | 0.323 | 0.287 | |
| Wact | 3.920 | 4.410 | 3.920 | 3.920 | 3.920 | 3.920 | 3.920 | 3.920 | 3.920 | 3.920 | |
| Qconv | 2.133 | 2.623 | 2.133 | 2.060 | 2.133 | 2.253 | 2.154 | 2.133 | 2.097 | 1.883 | |
| h(i) | 33.330 | 40.987 | 33.272 | 31.407 | 35.085 | 35.205 | 33.654 | 33.330 | 32.770 | 29.424 | |
| Indiv cont | 7.656 | -0.059 | -1.923 | 1.754 | 1.875 | 0.323 | 0.000 | – 0.560 | -3.906 | ||
| Squared | 58.618 | 0.003 | 3.698 | 3.077 | 3.516 | 0.104 | 0.000 | 0.314 | 15.259 | ||
| Abs Uncert | 9.197 | ||||||||||
| Rel Uncert | 28% | ||||||||||
Calculating the Uncertainty
To illustrate the process, consider an experiment measuring the average heat transfer coefficient to an electrically heated model of a component on a circuit board. The surrogate component is assumed to radiate to its surroundings, and conduct to the board. The electrical power to the component is measured using a wattmeter that requires correction. The local temperatures of the component, the coolant, the board, and the walls of the enclosure are measured using thermo-couples. Conduction heal loss is estimated using a conduction shape factor and the difference between the component and the board temperature. The radiation heat loss is calculated using the “tiny body” approximation, using the surface emissivity of the component. Conduction and radiation losses are subtracted from the corrected wattmeter reading to determine the convective heat transfer rate, and h is calculated based on the difference between component temperature and coolant temperature.
The names of the data items are listed in Column 1. The uncertainties associated with those measurements are in Col. 2 and the measured values in Col. 3. The next 9 columns are “pseudo” data sets; each made by perturbing one of the observed data bits by its uncertainty interval. The perturbed values are set in bold-faced type.
The first 5 lines in the second block calculate the conduction and radiation heat losses, the electrical power to the component, the convective heat transfer rate, and the apparent value of h. The value of h listed in Col. 3 is the “nominal” value: h calculated using the observed data. Block copying lhese equations across the 9 columns of perturbed data generates 9 additional estimates of h, one for each perturbed variable. The contribution to the overall uncertainty made by each variable is found by subtracting the nominal h from the perturbed h for that variable. The Root-Sum-Square of the individual contributions is the uncertainty in h (Col. 3, Abs. Uncert.). The relative uncertainty is the absolute uncertainty divided by the nominal value.
Interpreting the Calculated Uncertainty
This same spreadsheet could be used to estimate several different kinds of uncertainty depending on what kind of uncertainty estimates were provided in Col. 2. The uncertainty calculated in Col. 3 is always the same type as the inputs used in Col. 2: fixed errors, random errors, or uncertainties. If they were uncertainties, they could have been Zeroth Order, First Order, or Nth Order. The meaning of the calculated uncertainty cannot be interpreted until the type of input has been established.
Fixed Error: An error is considered “fixed” if its value is always the same on repeated observations at the same test condition with the same instruments and the same procedure. Fixed errors must often be estimated based on what is known about the precision of the instrument’s calibration, hence are often not statistically justifiable. The value used for the residual fixed error, after calibration, must have the same meaning as the 2![]() value (the 95% confidence level or 20/1 odds value) which would have been expected had the calibrations been repeated many times.Random Error: An error is considered “random” if its value is different on subsequent observations, and the difference varies randomly from trial to trial. There are few truly random processes above the molecular level. What appears to be random variation usually represents merely slow sampling of a fast process. In any case, the value used to describe the “random” error is the 2
value (the 95% confidence level or 20/1 odds value) which would have been expected had the calibrations been repeated many times.Random Error: An error is considered “random” if its value is different on subsequent observations, and the difference varies randomly from trial to trial. There are few truly random processes above the molecular level. What appears to be random variation usually represents merely slow sampling of a fast process. In any case, the value used to describe the “random” error is the 2![]() value expected for the population of measurements which might have been made.Uncertainty: The uncertainty in a measurement is defined as the Root-Sum-Square of its fixed error and its random error, as described above. It represents the interval within which the true value is believed to lie, accounting for both fixed and random errors.
value expected for the population of measurements which might have been made.Uncertainty: The uncertainty in a measurement is defined as the Root-Sum-Square of its fixed error and its random error, as described above. It represents the interval within which the true value is believed to lie, accounting for both fixed and random errors.
Zeroth Order Uncertainty: The uncertainty represented by the fixed and random errors introduced by the instrumentation alone, with no contribution from the process. The Zeroth Order Uncertainty is used to judge the fitness of the proposed instruments for the intended experiment. If the uncertainty in the result is unacceptably large, calculated using Zeroth Order inputs, then better instruments must be obtained.
First Order Uncertainty: The uncertainty contributed by short-term instability of the process as viewed through the instrumentation. First Order Uncertainty includes both process instability and the random component of instrument error. It is assessed by taking a set of 30 or more observations over a representative interval of time with the system running normally, using the normal instrumentation, and calculating the standard deviation of the set, ![]() . The First Order Uncertainty is 2
. The First Order Uncertainty is 2![]() . First Order Uncertainty estimates are used to judge the significance of scatter on repeated trials. If more than one of 20 repeated trials falls outside the First Order interval, this may suggest system changes.Nth Order Uncertainty: The overall uncertainty in the measurement accounting for process instability and the fixed and random errors in the instrumentation. Nth Order Uncertainty is calculated as the Root-Sum-Square of the fixed errors due to the instrumentation and the First Order Uncertainty. It represents the total range, around the reported value, within which the true value is believed to lie. The Nth Order Uncertainty is used in reporting the results in the literature, or comparing the presented result with a result from some other facility, or with some absolute truth (such as a Conservation of Energy test). The NthOrder Uncertainty should not be used to assess the significance of scatter, since the fixed errors do not change on repeated trials.
. First Order Uncertainty estimates are used to judge the significance of scatter on repeated trials. If more than one of 20 repeated trials falls outside the First Order interval, this may suggest system changes.Nth Order Uncertainty: The overall uncertainty in the measurement accounting for process instability and the fixed and random errors in the instrumentation. Nth Order Uncertainty is calculated as the Root-Sum-Square of the fixed errors due to the instrumentation and the First Order Uncertainty. It represents the total range, around the reported value, within which the true value is believed to lie. The Nth Order Uncertainty is used in reporting the results in the literature, or comparing the presented result with a result from some other facility, or with some absolute truth (such as a Conservation of Energy test). The NthOrder Uncertainty should not be used to assess the significance of scatter, since the fixed errors do not change on repeated trials.
Interpreting the Spreadsheet
In the present example, the nominal value of h is 33.3 W/m2oC with an uncertainty of 9.2 W/m2oC .
- If each input provided in Col. 2 represents the estimated Fixed Errors in that measurement, then the 9.2 represents the Fixed Error in h.
- If each input provided in Col. 2 represents the 2
 value from a set of repeated readings during the instrument’s calibration, then the 9.2 represents the instrumentation’s contribution to the Random Error in h.
value from a set of repeated readings during the instrument’s calibration, then the 9.2 represents the instrumentation’s contribution to the Random Error in h. - If each input provided in Col. 2 is the Root-Sum-Square of the Fixed and Random error in the instrumentation, then the 9.2 represents the Zeroth Order Uncertainty – the instrumentation’s contribution to the overall uncertainty in h.
- If each input provided in Col. 2 is the 2 value from a set of observations made with the system running, then the 9.2 represents the First Order Uncertainty in the result – the scatter which should be expected on repeated trials if the system does not change.
- If each input provided in Col. 2 is the Root-Sum-Square of the Fixed Error due to the instrumentation and the First Order Uncertainty, then the 9.2 represents the Nth Order Uncertainty in the result – the interval within which the true value is believed to lie.
Selected Readings
1. Moffat, R.J., “Contributions to the Theory of Single-Sample Uncertainty Analysis,” Trans. ASME, Journal of Fluids Engineering, Vol. 104, No. 2, pp. 250-260, June 1982.
2. Taylor, James L., Fundamentals of Measurement Error, Neff Instrument Corporation, 1988.
3. Dieck, Ronald H. Measurement, Uncertainty – Methods and Applications, Instrument Society of America, 1992.
4. ANSl/ASME PTC 19.1-1985, Instruments and Apparatus, Part 1, Measurement Uncertainty.
References:
1. Azar, K., and Russell, E.T., Effect of Component Layout and Geometry on Flow Distribution in Electronic Circuit Packs. ASME Journal of Electronic Packaging, vol. 113, p. 50-57, March 1991.
2. Wijk, J.J. van, A.J.S. Hin, W.C. de Leeuw, F.H. Post, Three Ways to Show 3D Fluid Flow. IEEE Computer Graphics and Applications, vol. 14, no. 5, p. 33~39, September 1994.
3 . Cabral, B. and L. Leedom, Imaging Vector Fields using Line Integral Convolution. Proceedings SIGGRAPH’93, Computer Graphics, vol.27, No.4, p.263-270, 1993.
4. Wijk, J.J. van, Spot Noise – Texture Synthesis for Data Visualization. Proceedings SlGGRAPH’91, Computer Graphics, vol. 25, No.4, p.309-318, 1991.

